Kerasの転移学習で航空会社の機体分類してみた
サマリ
- Kerasでの転移学習で航空機の画像分類をしてみた
- 精度は89%くらいだった
目的
最近機械学習の勉強を始めたので、n番煎じしつつ、画像分類をやってみたかった。
民間航空会社の機体画像を各会社で分類できるか試してみる。
環境
Python -V : Python 3.6.3 Machine : Ubuntu 16.04.5 LTS GPU : NVIDIA Corporation GK210GL [Tesla K80] (rev a1)
データ収集
今回は綺麗な航空機画像の投稿が多いFlyTeamというサイトからデータをスクレイピングする。
注意点
WEBスクレイピングの注意は以下のサイトが詳しい。
こちらを参考に以下のようにしている。
- アクセス毎に10秒スリープ
- (1枚の画像を取得するのに3回アクセスしているので30秒かかる計算)
- 集めた画像データの公開はしない
念の為、利用規約を確認すると、抵触しそうなのはこのあたり。
第四条(禁止行為)
ユーザーは当サイトの利用にあたって、以下の行為をしてはならないこととします。 事実に反する情報を登録・投稿すること 第三者・他のユーザー・当サイトの所有権、知的財産権などの財産的権利を侵害すること 第三者・他のユーザー・当サイトのプライバシーを侵害するか、又は、名誉・信用を毀損すること 第三者・他のユーザー・当サイトを誹謗中傷すること 当サイトの事前の同意なく、物品・サービスの広告宣伝など営利目的の行為をすること ウィルスプログラムや不正アクセスによりサービスの円滑な運営を妨害すること 当サイトが提供する情報・サービスを当サイトの承諾なくして複製・編集・頒布・転売などすること 当サイトの趣旨に関連のない情報を登録・投稿すること その他、公序良俗に反するか又は当サイトが不適切と判断する行為をすること 前項に該当する行為を行った場合には、当サイトの利用停止・投稿内容の削除・損害賠償請求など必要な措置を取ることとなります。その際、当サイトは一切>の法的責任を負わないものとします。
スクレイピングが明示的に禁止されているわけではないので、上記の通り迷惑がかからない程度のアクセスで頑張る。
データ集めるだけで1週間超かかった
画像データについて
今回は独断と偏見と好みで選んだ以下の20社の機体画像を分類してみる。
- 全日空(ana)
- アシアナ航空(asiana_airlines)
- ブリティッシュ・エアウェイズ(britishairways)
- キャセイパシフィック航空(cathay_pacific_airways)
- チャイナエアライン(china_airlines)
- 中国東方航空(china_eastern_airlines)
- 中国南方航空(china_southern_airlines)
- デルタ航空(delta)
- エバー航空(eva_airways)
- フェデックス・エクスプレス(fedex_express)
- フジドリームエアラインズ(fuji_dream_airlines)
- ジェイ・エア(j_air)
- 日本航空(jal)
- 大韓航空(koreanair)
- ルフトハンザドイツ航空(lufthansa)
- カタール航空(qatar_airways)
- シンガポール航空(singapore_airlines)
- スカイマーク(skymark)
- ユナイテッド航空(united)
- ベトナム航空(vietnam_airlines)
また、取得画像については以下のルールとした。
予想としては日本航空とジェイ・エアの識別は難しそうだし、航空連合は無理3だと思う。
実装
import requests, re, time, os from bs4 import BeautifulSoup import lxml.html # 待ち時間 wait_time = 10 # 何ページからとるか first_page = 2 # 何ページ分まで取るか last_page = 61 # 画像フォルダのパス image_path = "images/" # ディレクトリも作っておく os.mkdir(image_path) # 写真名のパターン pattern = "[0-9]+" companys = ["ana", "asiana_airlines", "britishairways", "cathay_pacific_airways", "china_airlines"\ , "china_eastern_airlines", "china_southern_airlines", "delta", "eva_airways", "fedex_express"\ , "fuji_dream_airlines", "j_air", "jal", "koreanair", "lufthansa"\ , "qatar_airways", "singapore_airlines", "skymark", "united", "vietnam_airlines"] for company in companys: # imagesディレクトリの下に各社のディレクトリを作成 os.mkdir(image_path + company) # 各社のURLは社名が"-"でつながっているがディレクトリ名には使えないので変換 company_url = company.replace("_", "-") for i in range(first_page, last_page+1): try: print(str(i) + " : page") # これだと1ページ目の画像は取れないが、枚数があればいいので細かいことは気にしない page_url = "https://flyteam.jp/airline/" + company_url + "/photo?pageid=" + str(i) r1 = requests.get(page_url) time.sleep(wait_time) # 画像URLを取得 soup = BeautifulSoup(r1.text,'lxml') img_url = soup.find_all('img',src=re.compile('^https://freighter.flyteam.jp/photo/')) # 投稿画像はリストの3個目から20個目まで for img in img_url[1:-4]: # FlyTeamの投稿写真にはユニークな番号が付与される模様 # 選別時に便利なように写真の番号を取得してそれをファイル名にする photo_number = re.search(pattern, img["src"]) photo_number = photo_number.group() #print(photo_number) # 選別の際の便利さのためにサムネではなくオリジナルを取得 ## 画像URLを取得 photo_url = "https://flyteam.jp/photo/" + str(photo_number) r2 = requests.get(photo_url) time.sleep(wait_time) soup = BeautifulSoup(r2.text,'lxml') img = soup.find_all('img',src=re.compile('^https://freighter.flyteam.jp/photo/')) ## 画像取得 r3 = requests.get(img[0]['src']) ## 保存 with open(image_path + company + "/" + str(photo_number) + str('.jpeg'),'wb') as file: file.write(r3.content) time.sleep(wait_time) except: pass print("complete!!")
まず各社1200枚の画像をスクレイピングして、定めたルールを満たすか目視で確認していった。
(とても辛かった。ルールを満たす画像かどうかを見分ける分類器を作る方が先だったのでは)
弾いた後1000枚に満たない場合は、スクリプトをちょいちょい書き換えて再度スクレイピングという手順を踏んだ。
最終的には各社1000枚ずつ、合計20000枚を集めた。
データの良し悪しについては目視なので正直なんとも言い難い。
このスクリプトと同じ階層にimagesフォルダがあり、その下に各社のディレクトリが作成される。
Kerasで転移学習
データが集まったところでKerasでモデルを作成する。
画像枚数が充分とは言えないので、学習済みモデルを使って新しくモデルを作成できる転移学習を行う。
Kerasには、ImageNetで学習したVGG16という画像分類モデルがあるのでそれを使うことにした。
実装
必要なモジュールのインポートと画像データの読み込みをする。
import os import cv2 import numpy as np import matplotlib.pyplot as plt from keras.utils.np_utils import to_categorical from keras.layers import Dense, Dropout, Flatten, Input, BatchNormalization from keras.applications.vgg16 import VGG16 from keras.models import Model, Sequential from keras import optimizers companys = ["ana", "asiana_airlines", "britishairways", "cathay_pacific_airways", "china_airlines", "china_eastern_airlines", "china_southern_airlines", "delta", "eva_airways", "fedex_express", "fuji_dream_airlines", "j_air", "jal", "koreanair", "lufthansa", "qatar_airways", "singapore_airlines", "skymark", "united", "vietnam_airlines"] img_list = [] y = [] for index,c in enumerate(companys): print("read images : " + c) img_path = os.listdir("images/" + c + "/") path = "images/" + c + "/" for i in range(len(img_path)): img = cv2.imread(path + img_path[i]) img = cv2.resize(img, (224,224)) img_list.append(img) y.append(index) X = np.asarray(img_list) y = np.asarray(y) rand_index = np.random.permutation(np.arange(len(X))) X = X[rand_index] y = y[rand_index]
集めた画像データの8割を学習データ、2割をテストデータに分割、ラベルをOne-hot表現にする。
# データの分割 X_train = X[:int(len(X)*0.8)] y_train = y[:int(len(y)*0.8)] X_test = X[int(len(X)*0.8):] y_test = y[int(len(y)*0.8):] # One-hot表現に変換 y_train = to_categorical(y_train) y_test = to_categorical(y_test)
VGG16のモデルをインポートして、最後の全結合層を外す。
最後の層を連結して、VGG16の重みは固定でコンパイル、学習させる。
# vgg16インスタンス作成 input_tensor = Input(shape=(224, 224, 3)) vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=input_tensor) # モデル定義 top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(256, activation='relu')) top_model.add(BatchNormalization()) top_model.add(Dropout(rate=0.5)) # 20社の分類なので20 top_model.add(Dense(20, activation='softmax')) # 連結 model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output)) # 重み固定 for layer in model.layers[:15]: layer.trainable = False # コンパイル model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy']) # 学習 history = model.fit(X_train, y_train, batch_size=100, epochs=20, validation_data=(X_test, y_test))
学習曲線や予測を可視化する。
# 学習状況の可視化 plt.plot(history.history['acc'], label='acc', ls='-', marker='o') plt.plot(history.history['val_acc'], label='val_acc', ls='-', marker='x') plt.ylabel('accuracy') plt.xlabel('epoch') plt.suptitle('training late', fontsize=12) plt.show() # 画像を一枚受け取り判定して返す関数 def pred_plane(img): line_name = ["ana", "asiana", "britishairways", "cathay_pacific", "china", "china_eastern", "china_southern", "delta", "eva", "fedex_express", "fuji_dream", "j_air", "jal", "koreanair", "lufthansa", "qatar", "singapore", "skymark", "united", "vietnam"] pred = np.argmax(model.predict(img.reshape(1, 224, 224, 3))) pred = line_name[pred] return pred # 精度の評価 scores = model.evaluate(X_test, y_test, verbose=1) print('Test loss:', scores[0]) print('Test accuracy:', scores[1]) # 予測 plt.figure(figsize=(15,15)) for i in range(30): img = X_test[i] plt.subplot(5,6,i+1) b,g,r = cv2.split(img) img = cv2.merge([r,g,b]) plt.imshow(img) plt.title(pred_plane(img)) plt.subplots_adjust(hspace=0.3) plt.show()
結果
精度は大体89%くらいだった。
Train on 16000 samples, validate on 4000 samples Epoch 1/15 16000/16000 [==============================] - 288s - loss: 3.1556 - acc: 0.2229 - val_loss: 1.5626 - val_acc: 0.5597 Epoch 2/15 16000/16000 [==============================] - 279s - loss: 1.5584 - acc: 0.5569 - val_loss: 0.9536 - val_acc: 0.7375 Epoch 3/15 16000/16000 [==============================] - 280s - loss: 1.0565 - acc: 0.7004 - val_loss: 0.7571 - val_acc: 0.8015 Epoch 4/15 16000/16000 [==============================] - 280s - loss: 0.8212 - acc: 0.7654 - val_loss: 0.6564 - val_acc: 0.8263 Epoch 5/15 16000/16000 [==============================] - 279s - loss: 0.6800 - acc: 0.8055 - val_loss: 0.6023 - val_acc: 0.8442 Epoch 6/15 16000/16000 [==============================] - 279s - loss: 0.5884 - acc: 0.8352 - val_loss: 0.5489 - val_acc: 0.8552 Epoch 7/15 16000/16000 [==============================] - 280s - loss: 0.5139 - acc: 0.8530 - val_loss: 0.5162 - val_acc: 0.8705 Epoch 8/15 16000/16000 [==============================] - 280s - loss: 0.4553 - acc: 0.8749 - val_loss: 0.4848 - val_acc: 0.8762 Epoch 9/15 16000/16000 [==============================] - 281s - loss: 0.4020 - acc: 0.8912 - val_loss: 0.4706 - val_acc: 0.8795 Epoch 10/15 16000/16000 [==============================] - 280s - loss: 0.3707 - acc: 0.9013 - val_loss: 0.4524 - val_acc: 0.8850 Epoch 11/15 16000/16000 [==============================] - 280s - loss: 0.3282 - acc: 0.9116 - val_loss: 0.4376 - val_acc: 0.8890 Epoch 12/15 16000/16000 [==============================] - 280s - loss: 0.3030 - acc: 0.9209 - val_loss: 0.4295 - val_acc: 0.8925 Epoch 13/15 16000/16000 [==============================] - 280s - loss: 0.2732 - acc: 0.9311 - val_loss: 0.4231 - val_acc: 0.8935 Epoch 14/15 16000/16000 [==============================] - 280s - loss: 0.2609 - acc: 0.9323 - val_loss: 0.4117 - val_acc: 0.8940 Epoch 15/15 16000/16000 [==============================] - 281s - loss: 0.2345 - acc: 0.9396 - val_loss: 0.3998 - val_acc: 0.8970 4000/4000 [==============================] - 62s Test loss: 0.399818249464 Test accuracy: 0.897
学習率はこんな感じ。
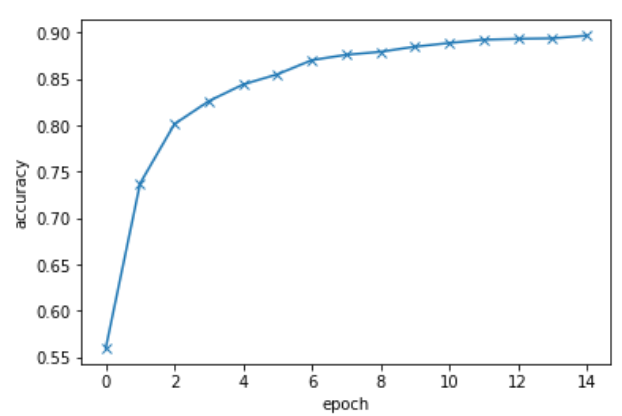
ランダムに30枚見てみる。

そんなに悪くなさそう!
難しいのではないかという予測を立てた日本航空とジェイ・エアを個別に見てみる。

大韓航空……?
日本航空⇔ジェイ・エアでの誤認識というより大韓航空との誤認識のほうが強い様子。
ノーマル塗装の方がしっかり認識できているようにみえるものの、特別塗装や航空連合が全く識別できていないわけでもなさそう。
意外と夜の流し撮りはしっかりと認識している。
なるほど、分からん。
感想
Kerasは日本語の参考情報が多くて初心者にもわかりやすかった。
今回はとりあえず各社1000枚ずつ、最低限のルールのもとデータを揃えたが、例えば次のようにしてみると精度は上がるかもしれない。
- 特別塗装機や夜の写真の枚数を各社同じにする(あるいは完全に省く)
- 航空連合塗装のみのデータで各社の機体を学習する
- もっと学習データを増やす、あるいは
ImageDataGeneratorで画像の水増しをする
なお、データ集めのための分類器が(略
参考
- VGG16を転移学習させて「まどか☆マギカ」のキャラを見分ける
- 機械学習によるギター画像の分類 その1
- Aidemy
- Premium Planの下記講座
- 男女認識
- CNN
- Premium Planの下記講座